Next: Best practice in pre-editing Up: Project and Media Attributes Previous: Audio attributes Contents Index
W Ratio =
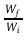 H Ratio =
H Ratio =
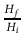
with Wf/Hf: final Width and Height; Wi/Hi: initial Width and Height.
The new canvas size is recalculated based upon a certain factor in the W Ratio, H Ratio fields. A practical use-case: the current resolution is 640×480, and for some reason you want Width to be 1.33 times bigger. You don't have to calculate what 640×1.33 is; you type 1.33 into the Width input instead, and CINELERRA-GG calculates it for you. W/H Ratio works as a local calculator. Warning: if you vary W/H Ratio without adjusting Display aspect ratio, we may get non-square pixels resulting in anamorphic frame distortion.
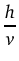 (the number of horizontal pixels divided into the number of vertical pixels). If the aspect ratio differs from the results of the formula above, your output will be in non-square pixels.
(the number of horizontal pixels divided into the number of vertical pixels). If the aspect ratio differs from the results of the formula above, your output will be in non-square pixels.
In order to do effects which involve alpha channels , a colormodel with an alpha channel must be selected. These are RGBA-8 bit, YUVA-8 bit, and RGBA-Float. The 4 channel colormodels are slower than 3 channel colormodels, with the slowest being RGBA-Float. Some effects, like fade, work around the need for alpha channels while other effects, like chromakey, require an alpha channel in order to be functional. So in order to get faster results, it is always a good idea to try the effect without alpha channels to see if it works before settling on an alpha channel and slowing it down.
When using compressed footage, YUV colormodels are usually faster than RGB colormodels . They also destroy fewer colors than RGB colormodels. If footage stored as JPEG or MPEG is processed many times in RGB, the colors will fade whereas they will not fade if processed in YUV. Years of working with high dynamic range footage has shown floating point RGB to be the best format for high dynamic range. 16 bit integers were used in the past and were too lossy and slow for the amount of improvement. RGB float does not destroy information when used with YUV source footage and also supports brightness above 100 %. Be aware that some effects, like Histogram, still clip above 100 % when in floating point. See also 17.3, 17.4 and A.3.